Summer 2027: Open to research internships; interested in academic-industry joint research in pre-training, distillation, and multimodal applications.
Contact: aengus.ng8@gmail.com
I work on efficient, scalable, and controllable generative modeling as a principled route to machine intelligence beyond human levels.
Research Statement
My long-term goal is to build systems capable of understanding, reasoning, planning, and acquiring physical intuition about the world, while designed to be efficient, scalable, and controllable.
Research Ownership: I can independently lead the entire research lifecycle for top-tier conferences, driving projects from problem formulation and experimentation through final publication.
Outside the Lab
I enjoy the combination of mathematics, coding, and intuition. Away from the keyboard, you can find me clearing my mind on long-distance runs 🏃♂️
QualcommJohns Hopkins UniversityRutgers UniversityUniversity of Wisconsin-MadisonAbstractPDF
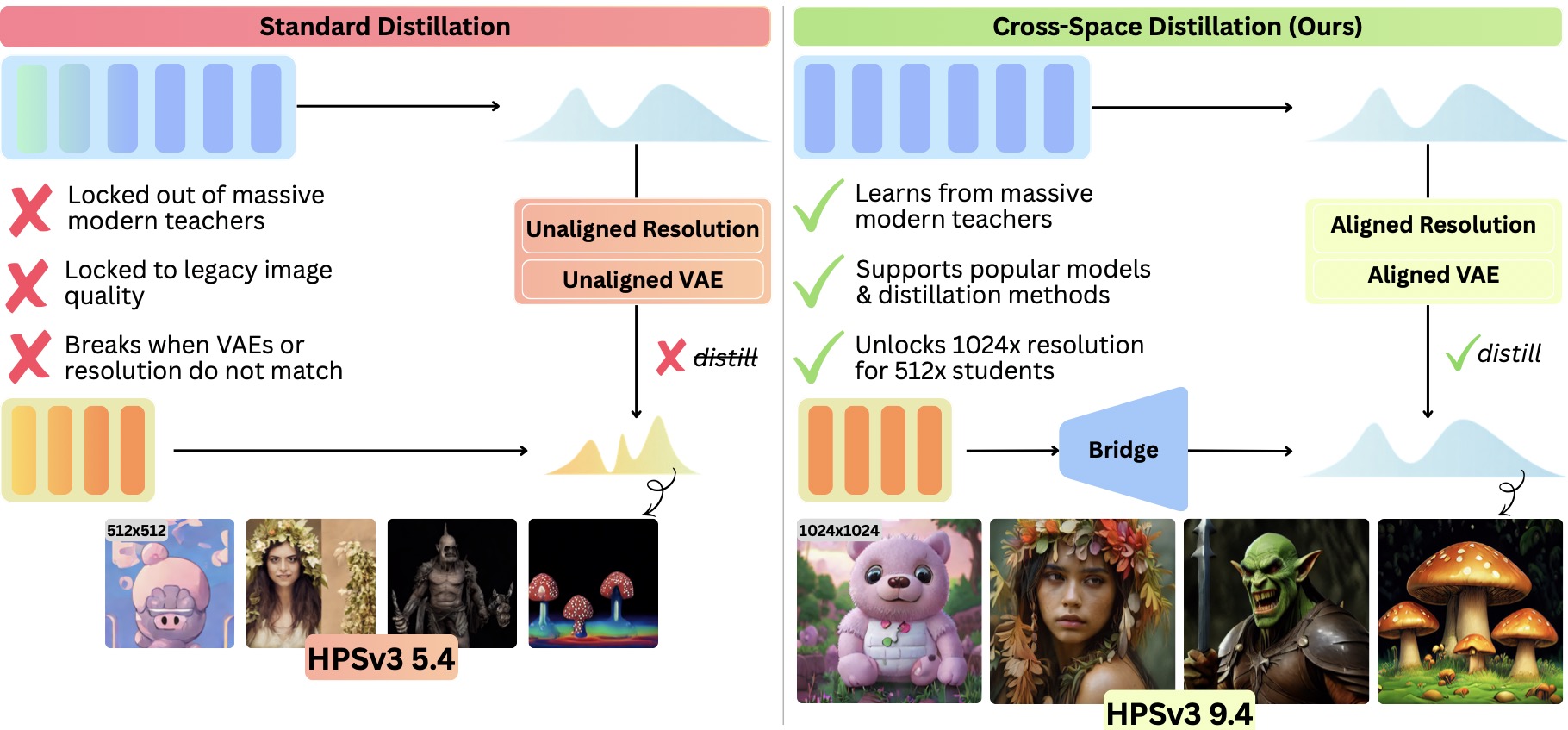
This work removes a hidden constraint in fast diffusion distillation: Teacher and Student no longer need to live in the same latent space. We formalize Cross-Space Distillation and introduce Bridge B_phi, a lightweight latent-space interface that makes standard one-step distillation possible across mismatched resolutions, VAEs, architectures, and diffusion/flow paradigms.
Shortcut models represent a promising, non-adversarial paradigm for generative modeling, uniquely supporting one-step, few-step, and multi-step sampling from a single trained network. However, their widespread adoption has been stymied by critical performance bottlenecks. This paper tackles the five core issues that held shortcut models back: (1) the hidden flaw of compounding guidance, which we are the first to formalize, causing severe image artifacts; (2) inflexible fixed guidance that restricts inference-time control; (3) a pervasive frequency bias driven by a reliance on low-level distances in the direct domain, which biases reconstructions toward low frequencies; (4) divergent self-consistency arising from a conflict with EMA training; and (5) curvy flow trajectories that impede convergence. To address these challenges, we introduce iSM, a unified training framework that systematically resolves each limitation. Our framework is built on four key improvements: Intrinsic Guidance provides explicit, dynamic control over guidance strength, resolving both compounding guidance and inflexibility. A Multi-Level Wavelet Loss mitigates frequency bias to restore high-frequency details. Scaling Optimal Transport (sOT) reduces training variance and learns straighter, more stable generative paths. Finally, a Twin EMA strategy reconciles training stability with self-consistency. Extensive experiments on ImageNet 256 × 256 demonstrate that our approach yields substantial FID improvements over baseline shortcut models across one-step, few-step, and multi-step generation, making shortcut models a viable and competitive class of generative models.
CVPR
Anti-I2V: Safeguarding your photos from malicious image-to-video generation
Advances in diffusion-based video generation models, while significantly improving human animation, poses threats of misuse through the creation of fake videos from a specific person’s photo and text prompts. Recent efforts have focused on adversarial attacks that introduce crafted perturbations to protect images from diffusion-based models. However, most existing approaches target image generation, while relatively few explicitly address image-to-video diffusion models (VDMs), and most primarily focus on UNet-based architectures. Hence, their effectiveness against Diffusion Transformer (DiT) models remains largely under-explored, as these models demonstrate improved feature retention, and stronger temporal consistency due to larger capacity and advanced attention mechanisms. In this work, we introduce Anti-I2V, a novel defense against malicious human image-to-video generation, applicable across diverse diffusion backbones. Instead of restricting noise updates to the RGB space, Anti-I2V operates in both the L*a*b* and frequency domains, improving robustness and concentrating on salient pixels. We then identify the network layers that capture the most distinct semantic features during the denoising process to design appropriate training objectives that maximize degradation of temporal coherence and generation fidelity. Through extensive validation, Anti-I2V demonstrates state-of-the-art defense performance against diverse video diffusion models, offering an effective solution to the problem.
ICLR
Revisit Visual Prompt Tuning: The Expressiveness of Prompt Experts
In International Conference on Learning Representations, 2026
QualcommThe University of Texas at AustinAbstractPDF
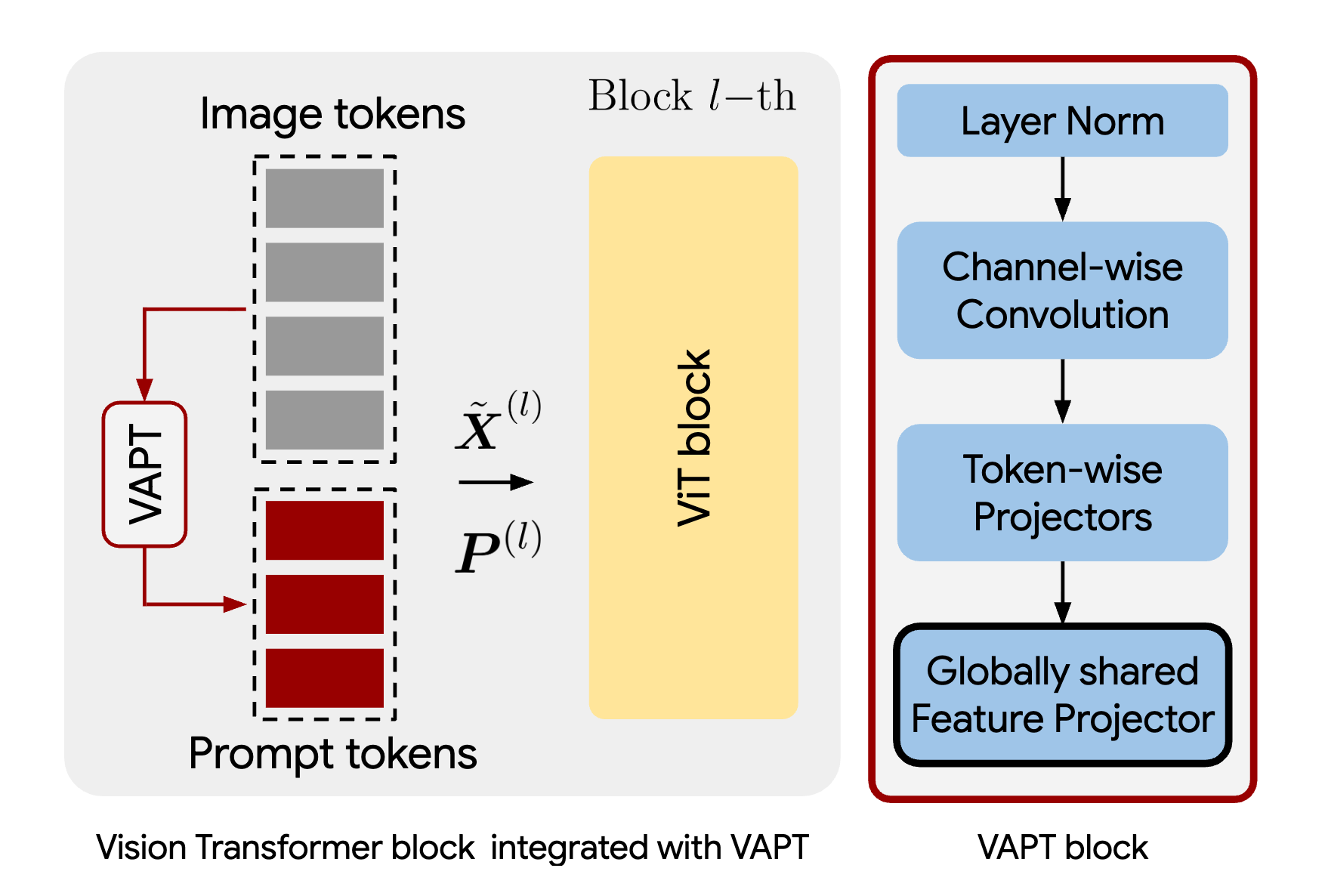
Visual Prompt Tuning (VPT) has proven effective for parameter-efficient adaptation of pre-trained vision models to downstream tasks by inserting task-specific learnable prompt tokens. Despite its empirical success, a comprehensive theoretical understanding of VPT remains an active area of research. Building on the recently established connection between Mixture of Experts (MoE) and prompt-based methods, wherein each attention head can be conceptualized as a composition of multiple MoE models, we reinterpret VPT as the introduction of new prompt experts into these MoE structures. We identify a key limitation in existing VPT frameworks: the restricted functional expressiveness of prompt experts, which remain static and thus limited in their adaptability. To address this, we propose Visual Adaptive Prompt Tuning (VAPT), a novel method that endows prompt experts with enhanced expressiveness while preserving parameter efficiency. Empirical evaluations on VTAB-1K and FGVC demonstrate that VAPT achieves substantial performance improvements, surpassing fully fine-tuned baselines by 7.34% and 1.04%, respectively. Moreover, VAPT consistently outperforms VPT while requiring fewer additional parameters. Furthermore, our theoretical analysis indicates that VAPT achieves optimal sample efficiency. Collectively, these results underscore the theoretical grounding and empirical advantages of our approach.
ICCV
Supercharged One-step Text-to-Image Diffusion Models with Negative Prompts
The escalating demand for real-time image synthesis has driven significant advancements in one-step diffusion models, which inherently offer expedited generation speeds compared to traditional multi-step methods. However, this enhanced efficiency is frequently accompanied by a compromise in the controllability of image attributes. While negative prompting, typically implemented via classifier-free guidance (CFG), has proven effective for fine-grained control in multi-step models, its application to one-step generators remains largely unaddressed. Due to the lack of iterative refinement, as in multi-step diffusion, directly applying CFG to one-step generation leads to blending artifacts and diminished output quality. To fill this gap, we introduce Negative-Away Steer Attention (NASA), an efficient method that integrates negative prompts into one-step diffusion models. NASA operates within the intermediate representation space by leveraging cross-attention mechanisms to suppress undesired visual attributes. This strategy avoids the blending artifacts inherent in output-space guidance and achieves high efficiency, incurring only a minimal 1.89% increase in FLOPs compared to the computational doubling of CFG. Furthermore, NASA can be seamlessly integrated into existing timestep distillation frameworks, enhancing the student’s output quality. Experimental results demonstrate that NASA substantially improves controllability and output quality, achieving an HPSv2 score of 31.21, setting a new state-of-the-art benchmark for one-step diffusion models.